Introduction
Puppet is one of the oldest IT automation tool based on Ruby. It’s used to configure, manage, deploy and orchestrate various applications accross your infrastructure.
Puppet comes with multiple built-in resources types (Puppet resources), that can perform almost any IT-driven automation task.
There are two deployment model :
- A master client model (most used model)
- A self contained standalone model (better for testing)
Puppet supports various OS like RedHat, CentOS, Ubuntu, Mac or Windows.
Codes in Puppet are idempotent and it is a declarative programming language. It makes it simple to understand.

How Puppet works ?
In a master-agent setup, the master is a Linux-based machine where we install and configure Puppet master software. This host is primarily responsible for maintaining configurations in the form of Puppet codes. The agents are the target machines managed by Puppet with the Puppet agent software installed on them. These could be all of the different servers in our environment that we wish to manage using Puppet. The agent node check regularly with the master node if anything needs to be updated in the agent (every 30 minutes).
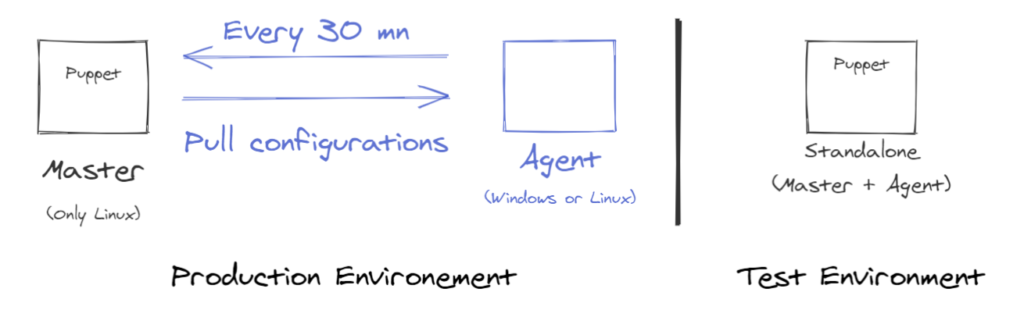
If anything needs to be updated, the agent pulls the necessary Puppet codes from the master and performs required actions. This mechanism is called a pull-based.
As seen previously, Ansible is a push-based model.
Puppet Workflow in details
Let us now understand the data flow through a quick example.
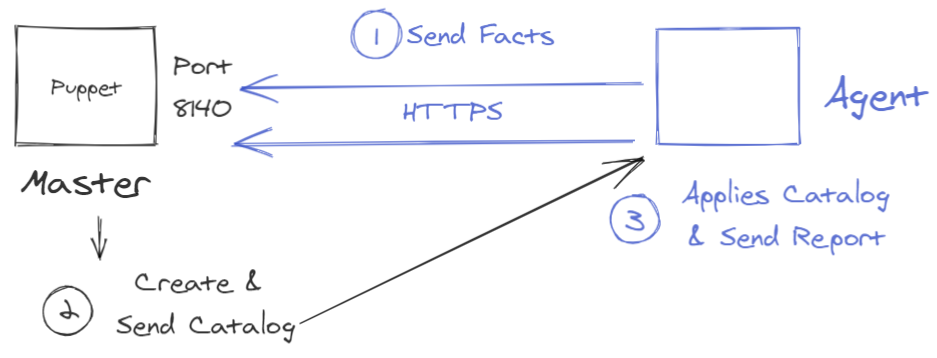
Puppet master is responsible for Puppet code management and contains different configurations in the environment. An administrator logs into the Puppet master to create or change Puppet codes. In our example, a DevOps engineer logs into the Pupet mater to create or change Puppet codes. The communication between master and agent is established through secure certificates. The Puppet master allows a secure connection with an agent on port 8140.
The connection is a 3 steps process :
- Once the connectivity is established between the agent and the master, the agent sends the data about its state (called facts) to the Puppet master. It can be its hostname, ip addresses, etc.
- Puppet uses the facts and compiles a list (called catalog) with the configuration to be applied to the agent. It can be changes related to a package installation, upgrades or removals, file system creation, server reboot etc.
- The master uses the catalog to perform actions on nodes, if any. After receiving the catalog, Puppet agent responds immediatly to the changes by executing the configuration plan and inform the Puppet master that’s done.
Inventory and Certificates
Once you have installed Puppet agent on nodes and Puppet master software on your Linux host, you now have to configure how they are going to communicate.
To let the master which are the client servers, we use Puppet configuration files and configure our master and client(s) like so :
# On the master node :
vi /etc/puppetlabs/puppet/puppet.conf
[main]
certname = puppet.example.com
server = puppet.example.com
# On the client node :
vi /etc/puppetlabs/puppet/puppet.conf
[main]
certname = agent01.example.com
server = puppet.example.com
# You can test connectivity
puppet agent --testWe also need to configure secured connectivity using SSL certificates. They are stored in the /etc/puppetlabs/puppet/ssl directory.
The following explained how it works and how to proceed :

If you don’t want to do it manually like explained previously, you can also create an autosign.conf file. It will automatically sign the requests the Puppet master gets from a pre-defined list of servers. It can be FQDN or wildcard names like *.example.com.
Do not forget to restart services after modifications 😉
That’s all for today !
Sources
puppet.com/docs

