Introduction
As you already know, Kubernetes is a great and popular container orchestrator. You can use its features to deploy your applications and it will take care of many things like scaling, rollouts and rollbacks or even self-healing as described below.
To do so, you will write manifests in YAML format (deployments, services, configmaps etc.) for each of your application to let Kubernetes know what to create.
These applications can be stateful or stateless.
Quick reminder, a stateless process or application does not save client data generated in one session for use in the next session with that client. There is no stored knowledge or reference to past transactions.
However, stateful applications can be returned to again and again. They’re performed with the context of previous transactions and the current transaction may be affected by what happened during previously.
Examples :
- Stateful application : a shop where each time you select an item and add it in your cart. It has to remind the state of your cart.
- Stateless application : an app used just for looking for an information in a database (i.e a weather forecast service.) Previous state is not relevant here because data is stored somewhere else.
To manage Stateful applications in Kubernetes, you will obviously need more “people” during their entire lifecycle.
For example, if you have several MySQL replicas, they will all have their own state and you won’t be able to update them in any order and all replicas must have a constant communication between them to let data consistent. Furthermore, even more manual operations will occur while scaling up or scaling down like network configuration for new replicas or removed replicas’ data management.
It means that you will need, for such configuration, people and skills to operate these applications !
And here is why you need Operators !
Operators role
You can see Operators as “Engineers” who would provide with software the skills of “Engineers”, who would encode in software, the skills of an expert administrator to perform things such as : how to deploy the app, how to recover it or how to create a cluster of my app ?
Just like Helm charts, Kubernetes Operators also package applications into easy-to-deploy bundles, but they do much more than that ! (we will see how they can be complementary later)
Indeed, you can use Kubernetes Operators to do things like deploy a stateful application and its database schema in a completely automatic way, or deploy an application across a cluster that is configured in a particular way to achieve high availability !
Think Operators as a great way to make things reusable and automated for stateful applications.
How Operators work ?
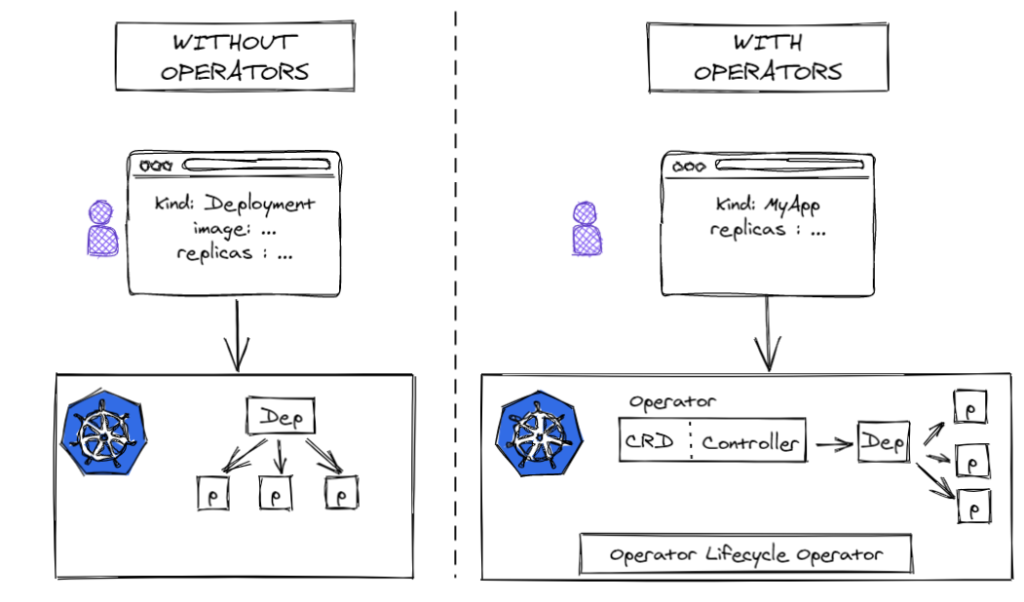
Operators work by extending the Kubernetes control plane and API. In its simplest form, an Operator adds an endpoint to the Kubernetes API, called a custom resource definition (CRD), along with a control plane component that monitors and maintains resources of the new type.
So the most common way to deploy an Operator is to add the Custom Resource Definition and its associated Controller to your cluster as described below :
Thus, Operators will have the same kind of loop as Kubernetes :
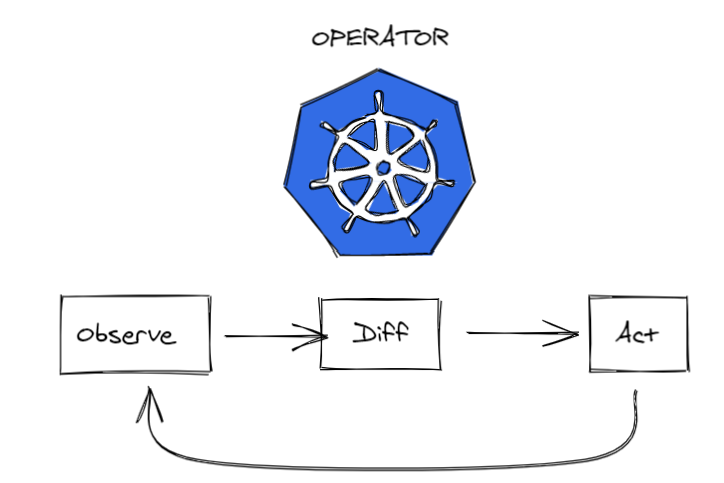
They will check for updates in the configuration file or noticed any changes or error and act as expected !
Helm vs Operators ?
When I discovered Operators I was kind of confused with Helm which both looked like a way of templating apps for me.
You don’t have to see Helm and Operators as competitors but as complementary or to be used in different types of use cases !
With Helm you can package your applications. Just like an RPM package on Linux ! So you can continue to use Helm when deploying a simple application and when few customizations are required.
However, you will still need Operators to perform actions described previously such as deploy stateful applications. It will then manage a set of instances, reconciling its state according according to the mentioned specs of its CR.
Helm can´t do that.
However, you can make them complementary while implementing your own Operators manually or through different frameworks !
How to create Operators ?
You can manually create Operators using an Operator SDK that allows you to build Kubernetes native applications. The Operator SDK, which is a Cloud Native Computing Foundation (CNCF) incubator project, makes managing Operators much easier by providing the tools to build, test, and package Operators.
The SDK currently incorporates three options for building an Operator:
- Go
- Ansible
- Helm
Here is a list of frameworks you can use in order to implement your own Operators :
- Operator-framework (CoreOS): https://github.com/operator-framework
- Kudo (D2iQ): https://github.com/kudobuilder/kudo
- Kubebuilder (Kubernetes SIGs group): https://github.com/kubernetes-sigs/kubebuilder
To conclude, you can find Operators written by the community through the following links :
Take a look !
Operators capabilities
In the chart below, we see how Operators that are built using Helm are only capable of managing installation and upgrades, while Ansible and Go are capable of managing a system’s entire lifecycle.
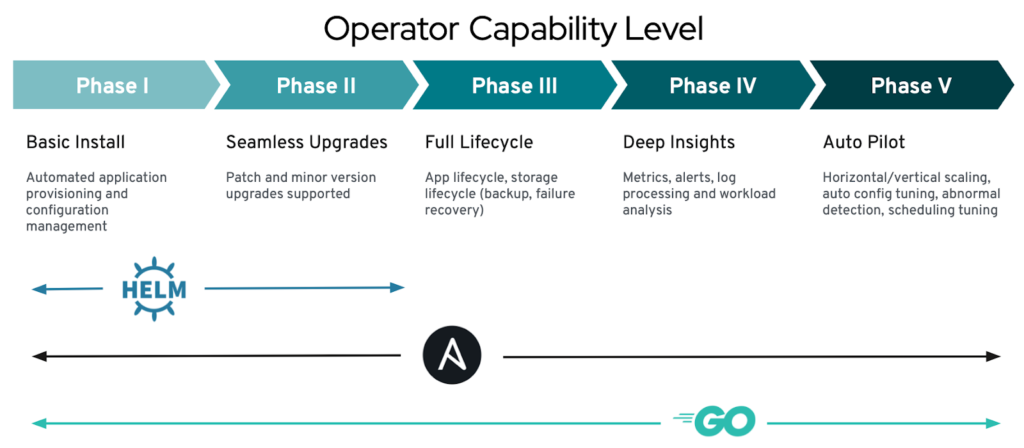
Here are an example for each phase of the capability level to help you understand their meaning :
- Basic Install : an Operator deploys a database through deployment, ServiceAccount, RoleBinding, Configmap, PersistentVolumeClaim and Secret objects while initializing an empty database.
- Seamless Upgrades : an Operator can upgrade an existing database to a newer version without data loss.
- Full Lifecycle : an Operator provides the ability to create a backup of the data.
- Deep Insights : an Operator parses logging output of the database and understands log events and produce alerts.
- Auto Pilot : an Operator monitors the query load of the database and automatically scales additional read-only secondary replicas up and down.
Operator example
A great Operator example would be Portworx in the cloud-native storage area. This cloud native storage solution provides high availability, data protection and security for containerized applications. It will allow you to migrate entire applications with their data accross clusters using a single kubectl command !
The Portworx Operator exports metrics which can be used with the Prometheus Operator to collect, alert and show Grafana dashboards of this data. It means that it brings Portworx Operator up to capability Phase IV (Deep Insight).
YAML, Helm, Kustomize, Operators – Which one should I use ?
All solutions have pros and cons.
As described on the table and graph below, you can easily get an idea of their complexity and their flexibility :
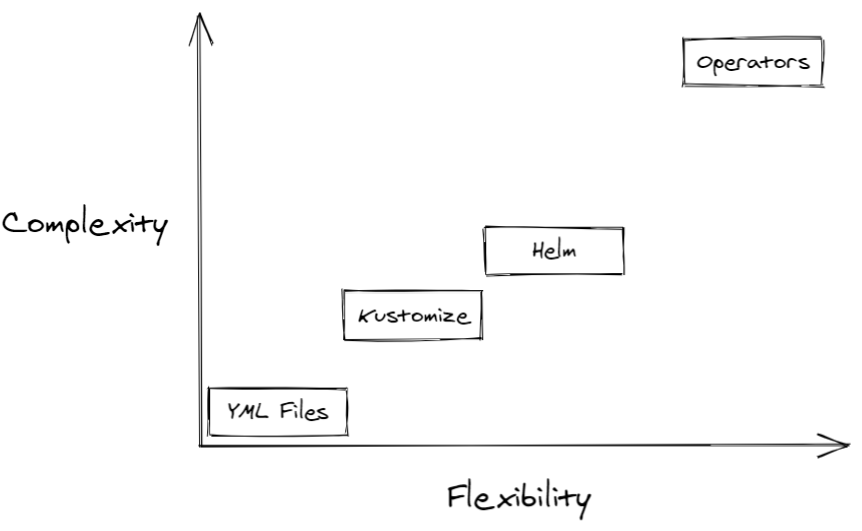
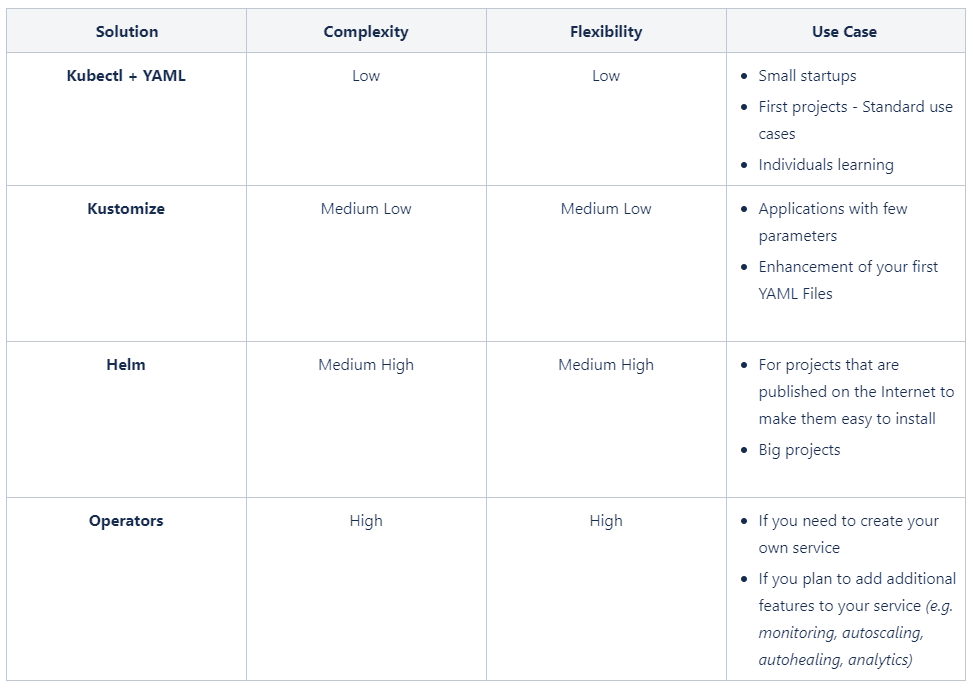
Conclusion
We have seen how interesting Operators could be, from the flexibility perspective, even if they can be complex. They can be used as a method of packaging, deploying and managing a Kubernetes application. The key attribute of an Operator is the management of the application including installation, upgrades, backups, insights or scaling !
It’s interesting to know that Operators are not equally used by Kubernetes distributions.
On the one hand, Openshift uses Operators for everything, it will bring operational knowledge to applications deployed. They even use Operators to configure Openshift’s web interface !
With Rancher, on the other hand, it’s the opposite choice which gives more flexibility and it may be easier for administrators because it won’t rely on Operators for everything.
To conclude, Operators may seem complicated but if well written, they will let you make your application “as a service” with a native complex logic handled by a simple YAML file !

